Python爬虫(一) 之Beautiful Soup
Updated:
Python爬虫(一) 之Beautiful Soup
今天想入门学python爬虫,同事推荐了一个不错的Python库——Beautiful Soup。嗯?你说什么?美味的汤?
官方文档的解释是:Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。
因此它是一个使用方便,可以用于网络爬虫的Python库。
今天试着体验了一番,确实好用~
1. 安装Beautiful Soup
如果你的系统是Ubuntu或Debain, 可以通过以下命令安装1$ apt-get install Python-bs4
或者可以选择用pip安装1$ pip install beautifulsoup4
如果有内网墙需要用proxy的,可以用下面的命令1$ pip install beautifulsoup4 --proxy="http://*****.com:port"
2. 创建 Beautiful Soup 对象
首先导入bs4库1from bs4 import BeautifulSoup
我们可以本地创建一个html文件作为获取的BeautifulSoup内容,或直接爬取网站上的内容。1soup = BeatifulSoup(html)
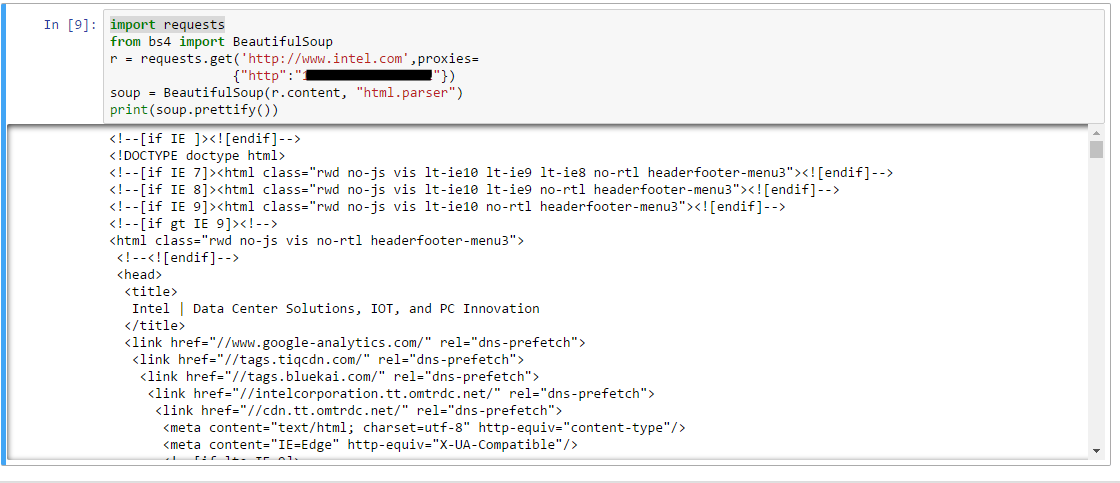
或者1234import requestsr = requests.get('http://www.intel.com',proxies= {"http":"*.*.*.*:***"})soup = BeautifulSoup(r.content, "html.parser")
然后,就可以把对象打印出来啦~
|
|
结果如下: